Qwen AI Usage and Download Statistics (2025)

If you’ve been keeping an eye on the AI space, you’ve probably heard of Qwen 2.5-Max – China’s latest AI model, built by Alibaba. This model isn’t just another chatbot; it’s a serious contender, taking on some of the biggest names in AI, like GPT-4o, DeepSeek-V3, and Llama-3.1-405B. Qwen 2.5-Max is designed to do more than just answer questions – it can control PCs and phones.
China is pushing hard to catch up and even beat American AI models, and Qwen 2.5-Max is proof. It’s already crossed DeepSeek in benchmarks and continues to grow. In fact, over 2.2 million companies and 90,000 enterprises have already been using Qwen AI, and it’s only just getting started. Read on to learn more about the key Qwen AI statistics, facts, and future possibilities.
Top Qwen AI Statistics (Editor’s Picks)
- Over 2.2 million corporate employees and 90,000 enterprises use Qwen AI as of 2025.
- Qwen AI models have over 7 million downloads on Hugging Face and GitHub.
- By December 2024, Qwen AI visits increased by 1114.64%, reaching 25,245 visits.
- Qwen 2.5-Max leads in benchmarks, outperforming GPT-4o, DeepSeek V3, and Llama 3.1-405B.
What is Qwen 2.5-Max?
Qwen 2.5-Max is the latest and most advanced AI model developed by Alibaba Cloud. It is the upgraded version of the original Qwen AI and is known for its high performance and efficiency. This model can perform a variety of tasks like natural language processing (NLP), coding, and mathematics, having sizes that range from 0.5 billion to 72 billion parameters. Qwen 2.5-Max was designed to compete with leading AI models like GPT-4o, Claude 3.5 Sonnet, and DeepSeek V3.
Qwen AI Versions and Upgrades
Alibaba’s Qwen series has seen several upgrades, each having its own set of capabilities and advancements:
| Release Date | Model Version | Description | Training Data (Tokens*) |
| July 2023 | Qwen (Tongyi Qianwen) | Initial beta release based on Meta AI’s Llama model. | N/A |
| December 2023 | Qwen1.5 | Enhanced performance and capabilities. | N/A |
| March 2024 | Qwen1.5-MoE-A2.7B | First mixture of expert models, improving efficiency. | N/A |
| June 2024 | Qwen2 | Significant improvements in instruction following and multilingual support. | N/A |
| September 2024 | Qwen2.5 | Expanded model sizes and enhanced capabilities. | Up to 18T tokens |
| January 2025 | Qwen2.5-VL | An advanced vision-language model capable of complex visual tasks. | Up to 18T tokens |
| January 2025 | Qwen2.5-Coder | Optimized for coding tasks, and trained on extensive code-related data. | 5.5T tokens (code data) |
| January 2025 | Qwen2.5-Math | Supports English and Chinese, uses advanced reasoning methods like CoT, PoT, and TIR. | Up to 18T tokens |
*Tokens are chunks of text that AI models process. A token can be as short as one character or as long as one word, depending on the language.
Source: Alibaba Cloud
Qwen AI User Statistics
Around 90,000 businesses use Qwen AI models. In addition, more than 2.2 million corporate users access Qwen-powered AI services through DingTalk, Alibaba’s platform for work collaboration and app development. Qwen models, which range from 0.5 billion to 110 billion parameters, have been very popular, with over 7 million downloads on platforms like Hugging Face and GitHub.
Meanwhile, ModelScope, China’s largest AI model community led by Alibaba Cloud, now hosts over 4,000 AI models and has a thriving community of

Source: Alibaba Cloud
Qwen AI Search Trends
People’s interest in Qwen AI saw a sharp increase in late January. Before this, the search volume was steady and low. However, towards the end of January, the search trend reached its peak close to 100 as shown below, indicating a significant rise in discussions, searches, or adoption of Qwen AI.
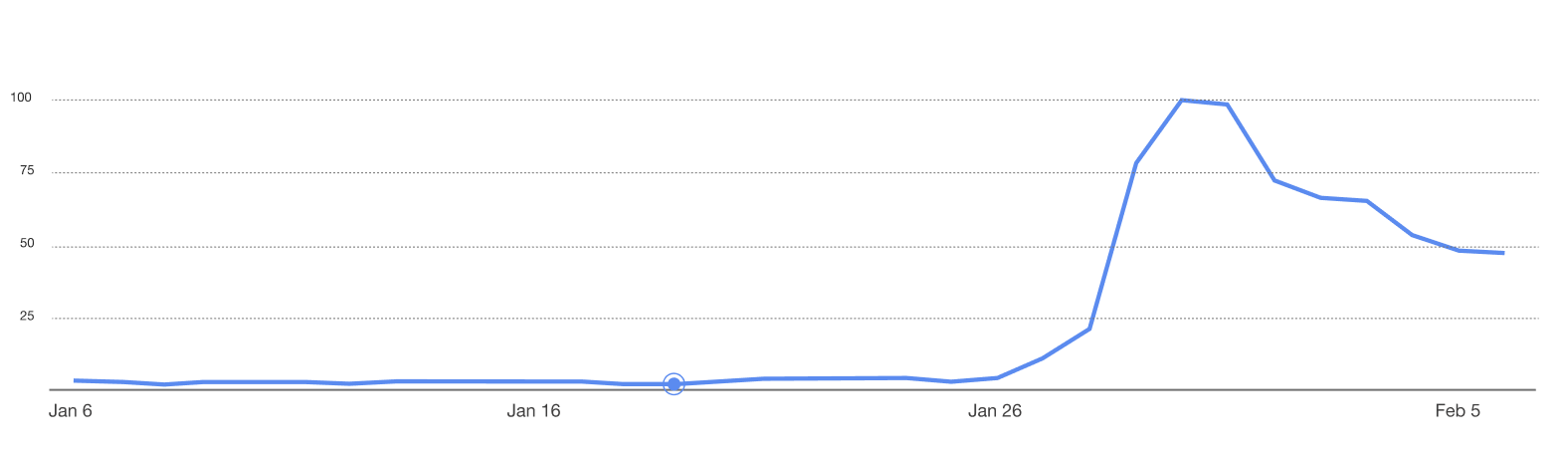
Source: Google Analytics
Qwen AI Traffic by Country
In December 2024, Qwen AI had 25,245 visits, a huge 1114.64% increase from the previous month. 65.95% of the users accessed it via mobile web, while 34.05% used desktops.
Iraq had the highest number of visits at 27.52%, followed by Brazil at 19.08%. Turkey, Russia, and the United States are also among the top countries with a decent number of visits.
Check out this table to see the top countries that visit Qwen AI:
| Country | Traffic Share |
| Iraq | 27.52% |
| Brazil | 19.08% |
| Turkey | 12.10% |
| Russia | 10.60% |
| United States | 6.15% |
Source: Similarweb
Qwen 2.5-Max Performance Metrics
Qwen 2.5-Max has been tested against other top AI models to see how well it performs in different tasks. These tests look at both “instruct models” (which are adjusted for specific tasks like chat and coding) and “base models” (which are the basic version before any adjustments). Knowing the difference helps understand the test results better.
Qwen 2.5-Max Instruct Models
When it came to instruct models, the following criteria were used to compare Qwen AI to other models.
| Benchmark | Explanation |
| Arena-Hard | Matches human preference in AI-generated responses. |
| MMLU-Pro | Measures knowledge and reasoning abilities of AI models. |
| GPQA-Diamond | Assesses general knowledge question-answering capabilities. |
| LiveCodeBench | Evaluates the coding ability of AI models. |
| LiveBench | Tests overall capabilities, indicating broad competence in real-world AI tasks. |
- Qwen AI came first Arena-Hard with a score of 89.4, ahead of DeepSeek V3 by 3.9 points and Claude3.5 Sonnet by 4.2 points.
- In GSM8K, Qwen 2.5-Max achieved 94.5, outperforming DeepSeek V3 by 5.2 points and Llama 3.1-405B by 5.5 points.
- For MMLU-Pro, it scored 76.1, staying close to GPT-4o, which scored 78.0, and surpassing DeepSeek V3 by 0.2 points.
- In LiveBench, Qwen 2.5-Max was on top with 62.2, slightly ahead of DeepSeek V3 by 1.7 points and GPT-4o by 1.9 points.
- In LiveCodeBench, its score was 38.7, very close to Claude’s 3.5 Sonnet, which scored 38.9.
Check out the chart below for a better understanding of how best Qwen AI works in comparison to other models:
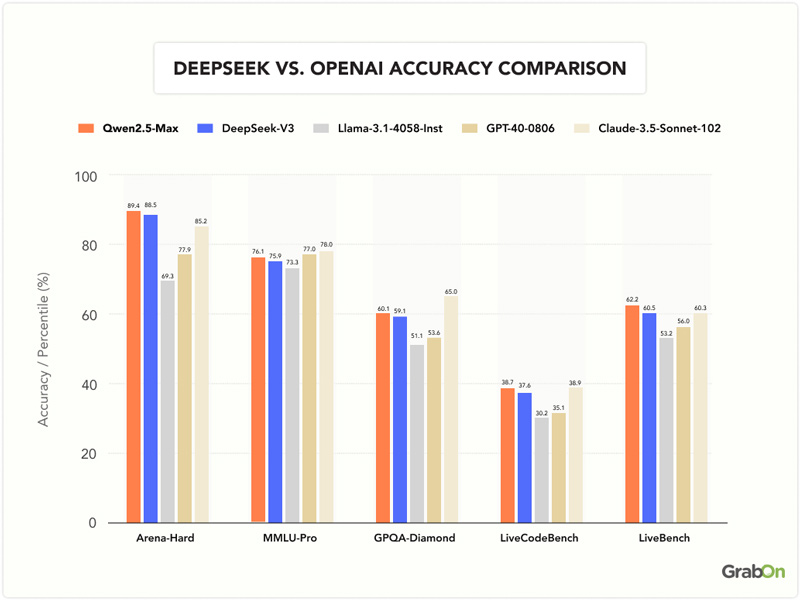
Source: QwenLM
Qwen 2.5-Max Base Models
When it came to base models, the following criteria were used to compare Qwen AI to other models.
| Benchmark | Explanation |
| MMLU | Measures general knowledge and language understanding. |
| MMLU-Pro | Assesses knowledge and reasoning abilities. |
| BBH | Evaluates broader language and comprehension skills. |
| C-Eval | Tests comprehensive evaluation skills in language and understanding. |
| CMMU | Focuses on a combination of knowledge and reasoning. |
| HumanEval | Assesses coding skills and problem-solving abilities. |
| MBPP | Measures performance in coding-related tasks and problem-solving. |
| CRUX-I | Evaluates the ability to follow instructions and generate solutions independently in coding tasks. |
| CRUX-O | Similar to CRUX-I, focusing on overall problem-solving in coding tasks. |
| GSM8K | Tests mathematical reasoning and problem-solving abilities. |
| MATH | Assesses more complex mathematical problem-solving skills. |
- Qwen 2.5-Max was the highest in MMLU, with a score of 87.9, crossing DeepSeek V3 and Llama 3.1-405B. In C-Eval, it scored 92.2, staying ahead of both models.
- In HumanEval, Qwen 2.5-Max scored 73.2, slightly higher than DeepSeek V3 and much better than Llama 3.1-405B. For MBPP, it received 80.6, leading in coding tasks.
- In GSM8K, Qwen 2.5-Max reached 94.5, crossing DeepSeek V3 by 5.2 points and Llama 3.1-405B by 5.5 points. On MATH, it scored 68.5, slightly ahead of its competitors.
The chart below shows how Qwen 2.5-Max outperforms other AI models in different areas:
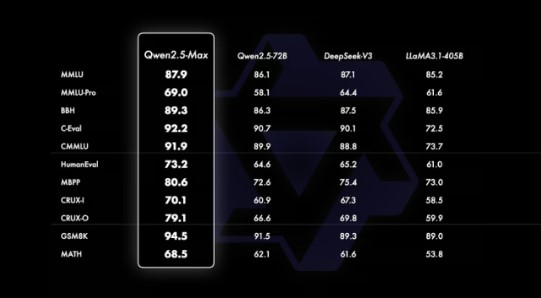
Source: QwenLM
Conclusion
Qwen 2.5-Max is highly advanced, thanks to improvements in data and model size, showing Alibaba’s dedication to top-level research. It is Alibaba’s best AI model so far and competes with top models like GPT-4o, Claude 3.5 Sonnet, and DeepSeek V3. Unlike some earlier versions, Qwen 2.5-Max is not open-source, but you can test it using Qwen Chat or through Alibaba Cloud’s API. With Alibaba’s ongoing investment in AI, it’s expected that future models, like a possible Qwen 3, will focus on better reasoning skills.



